
Principles of DoE: Randomization, Replication, Blocking
Will you reach the same conclusion twice?
When I did my PhD, from time to time I was quite happy about some results. They were exactly what I was hoping for. When I presented them to my supervisor, hoping for some sort of praise, he asked if I could repeat it… and I couldn’t… Maybe you know the feeling. So what to do about it? There are three fundamental principles that can help you avoid situations like this: replication, randomization, and blocking.
Replication
Replication is probably the most intuitive to understand. You repeat the same experiment multiple times. I know. We are all lazy. But it is actually more work not to include replications into your design.
Louise the R&D manager at tire.inc
Imagine yourself in the shoes of Louise. She is the R&D manager at a tire company, and they just developed a new rubber formula that supposedly makes cars more secure by providing better grip to the street, reducing braking distances in dangerous situations. How would you prove that? You would perform an experiment, of course. One break test with a normal tire and one break test with a tire made from the new rubber formula. But what if the driver was a little bit slow hitting the brake with your new tire? You see, the results might not be very reliable, and while you might get lucky, we don’t want luck determining the outcome of our experiments. We need to include replications.
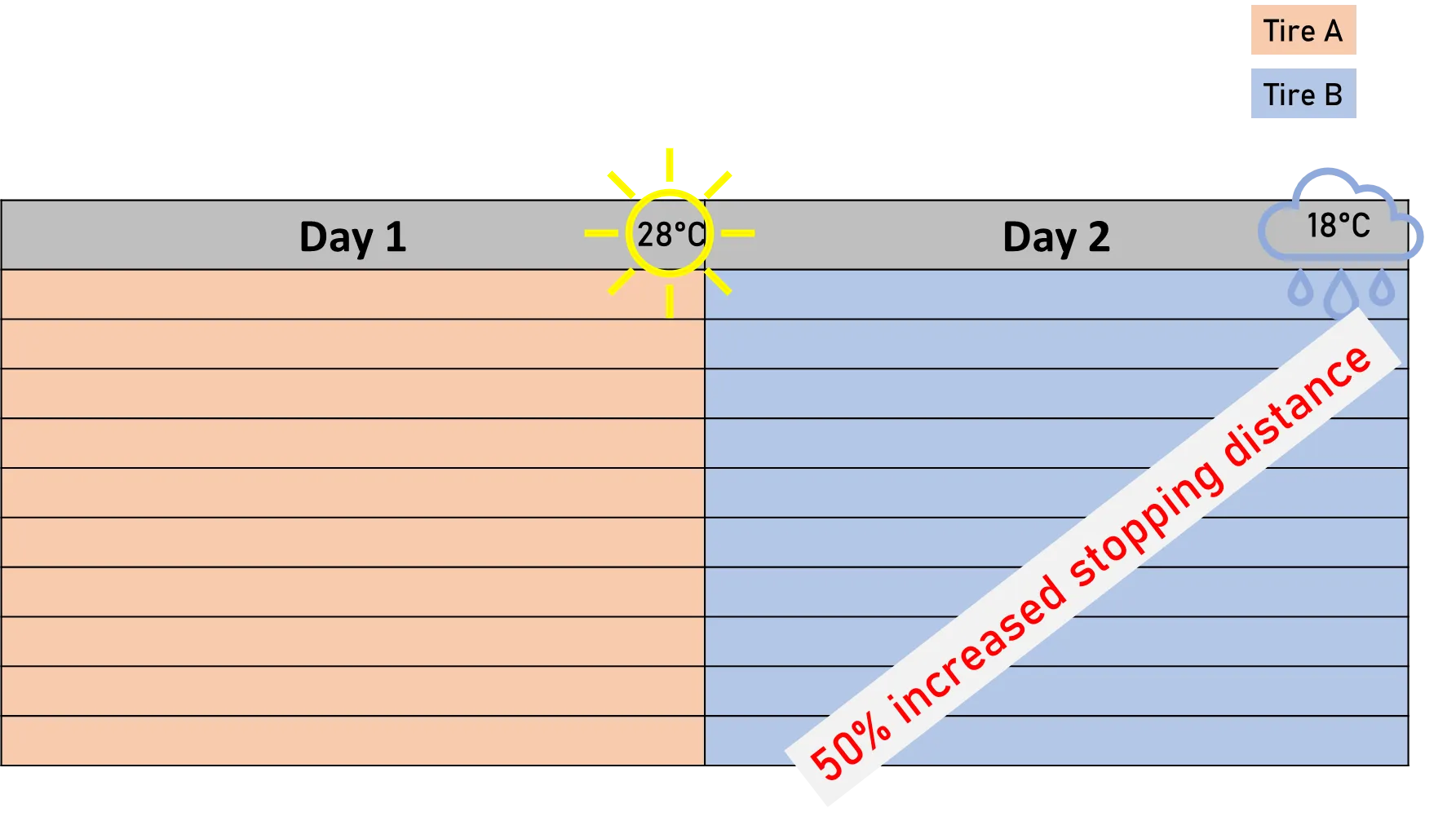
Randomization
Randomization might be less intuitive but equally important. It means conducting your experiments in a random order. As we acknowledged that we need replications for our break test experiment, we could just decide to perform all the tests with tire A first and then do all the tests with tire B. However, this approach carries the risk of introducing bias into the results. Bias is a systematic error that causes your results to be wrong in a consistent direction — too high, too low, or favoring one outcome over another.
How Louise avoids biased results
Imagine Louise again. She’s replicating the breaking test for each tire ten times, which also means she has to split the tests into two separate days. Now imagine it is raining one day but sunny the other. Would it be fair to perform all tests for tire A on the first day and all the tests for tire B on the second? Of course not. The slippery road would significantly increase the breaking distances for one tire, regardless of its properties just because of the outside conditions. We cannot have this kind of bias in our results; we need to split the tests for each tire equally across both days; we need to randomize them.
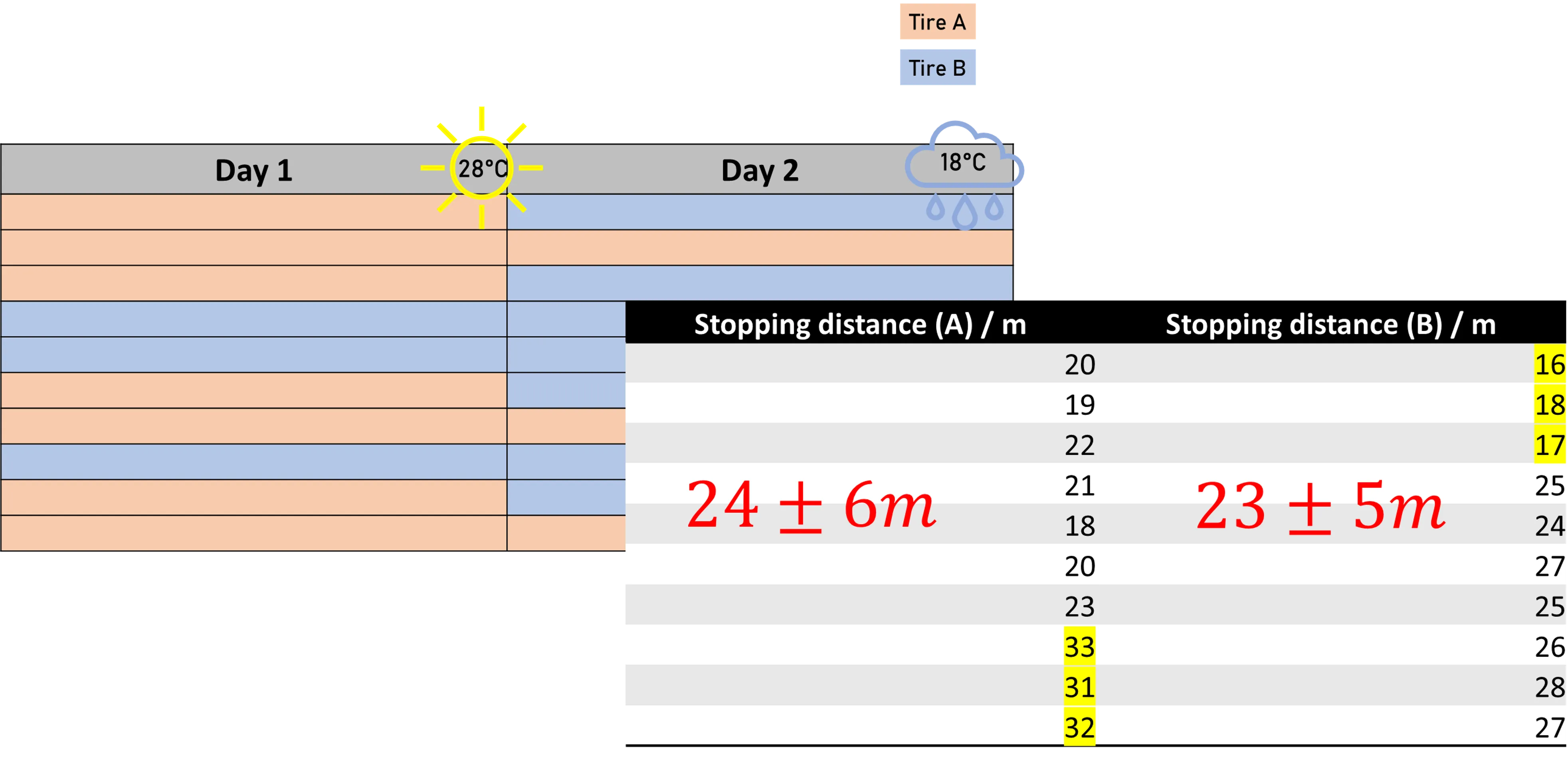
Blocking
But that will leave us with a third problem. The comparison between both tires might be fair, but the variability in the results is also high. The changing weather conditions cause the measured stopping distances to vary more than they normally would, making it harder to detect statistically significant differences between the tires.
Louise reduces variability through blocking
Back to Louise because she knows how to fix this variability issue. The solution is that instead of just splitting the tests equally across both days, you also need to group them by day when analyzing the data. This is called blocking. A block is a group of experimental conditions that are expected to affect the outcome, but are not the primary focus of the study. In Louise’s case, each day is a block because road and weather conditions vary from one day to the next. That way, we don’t let the variability from changing weather conditions blur the real differences between the tires.
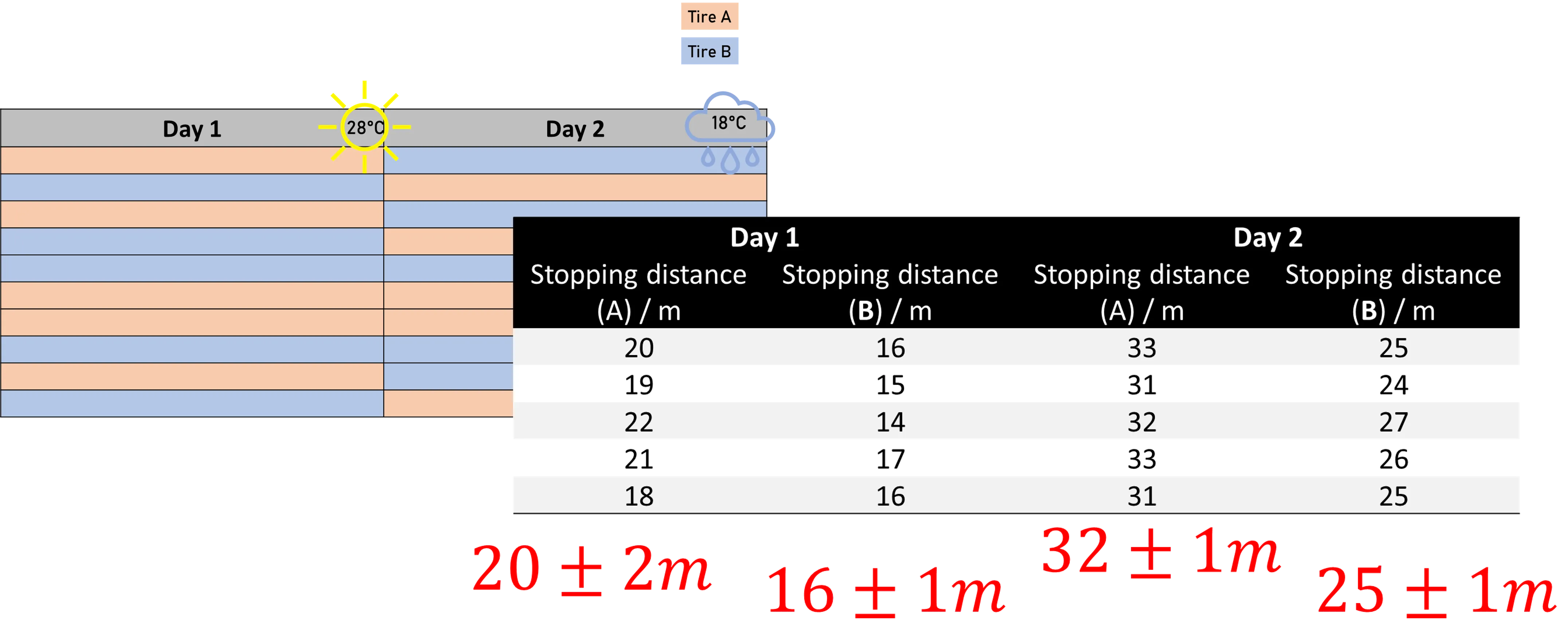
Bottom line
If you want to record reliable and high-quality data, you need to replicate some of your experimental runs to estimate natural variability (like the driver’s reaction time), randomize them to avoid bias from unknown influences (like changing weather conditions during the day), and group them into blocks to control known sources of variability (like performing the tests on two different days).
Now that your experiments are set up to deliver trustworthy data, it’s time to make sense of the results—starting with main effects and interactions.